Example Case using Racetrack¶
Below is an example of how to initialize the Racetrack environment and solve/compare with multiple solvers.
Boilerplate¶
If you’re playing with things under the hood as you run these, autoreload is always useful…
[1]:
%load_ext autoreload
%autoreload 2
If necessary, add directory containing lrl to path (workaround for if lrl is not installed as a package)
[2]:
import sys
# Path to directory containing lrl
sys.path.append('../')
[3]:
from lrl import environments, solvers
from lrl.utils import plotting
import matplotlib.pyplot as plt
Logging is used throughout lrl for basic info and debugging.
[4]:
import logging
logging.basicConfig(format='%(asctime)s - %(name)s - %(funcName)s - %(levelname)s - %(message)s',
level=logging.INFO, datefmt='%H:%M:%S')
logger = logging.getLogger(__name__)
Initialize an Environment¶
Initialize the 20x10 racetrack that includes some oily (stochastic) surfaces.
Note: Make sure that your velocity limits suit your track. A track must have a grass padding around the entire course that prevents a car from trying to exit the track entirely, so if max(abs(vel))==3, you need 3 grass tiles around the outside perimeter of your map. For track, we have a 2-tile perimeter so velocity must be less than +-2.
[5]:
# This will raise an error due to x_vel max limit
try:
rt = environments.get_racetrack(track='20x10_U',
x_vel_limits=(-2, 20), # Note high x_vel upper limit
y_vel_limits=(-2, 2),
x_accel_limits=(-2, 2),
y_accel_limits=(-2, 2),
max_total_accel=2,
)
except IndexError as e:
print("Caught the following error while building a track that shouldn't work:")
print(e)
print("")
# This will work
try:
rt = environments.get_racetrack(track='20x10_U',
x_vel_limits=(-2, 2),
y_vel_limits=(-2, 2),
x_accel_limits=(-2, 2),
y_accel_limits=(-2, 2),
max_total_accel=2,
)
print("But second track built perfectly!")
except:
print("Something went wrong, we shouldn't be here")
Caught the following error while building a track that shouldn't work:
Caught IndexError while building Racetrack. Likely cause is a max velocity that is creater than the wall padding around the track (leading to a car that can exit the track entirely)
But second track built perfectly!
Take a look at the track using plot_env
[6]:
plotting.plot_env(env=rt)
[6]:
<matplotlib.axes._subplots.AxesSubplot at 0x1f32321ae48>

There are also additional maps available - see the racetrack code base for more
[7]:
print(f'Available tracks: {list(environments.racetrack.TRACKS.keys())}')
Available tracks: ['3x4_basic', '5x4_basic', '10x10', '10x10_basic', '10x10_all_oil', '15x15_basic', '20x20_basic', '20x20_all_oil', '30x30_basic', '20x10_U_all_oil', '20x10_U', '10x10_oil', '20x15_risky']
Tracks are simply lists of strings using a specific set of characters. See the racetrack code for more detail on how to make your own
[8]:
for line in environments.racetrack.TRACKS['20x10_U']:
print(line)
GGGGGGGGGGGGGGGGGGGG
GGGGGGGGGGGGGGGGGGGG
GGG OOOO GG
GGG GGGG GG
GGOOOOGGGGGGGGOOOOGG
GGOOOGGGGGGGGGGOOOGG
GG GGGGGGGG GG
GG SGGGGG GG
GGGGGGGGGGGGGGFFFFGG
GGGGGGGGGGGGGGFFFFGG
We can draw them using character art! For example, here is a custom track with more oil and a different shape than above…
[9]:
custom_track = \
"""GGGGGGGGGGGGGGGGGGGG
GGGGGGGGGGGGGGGGGGGG
GGGOOOOOOOOOOOOOOOGG
GGG GGGG GG
GG GGGGGGGG GG
GGOOOOOOSGGGGGOOOOGG
GGGGGGGGGGGGGGFFFFGG
GGGGGGGGGGGGGGFFFFGG"""
custom_track = custom_track.split('\n')
[10]:
rt_custom = environments.get_racetrack(track=custom_track,
x_vel_limits=(-2, 2),
y_vel_limits=(-2, 2),
x_accel_limits=(-2, 2),
y_accel_limits=(-2, 2),
max_total_accel=2,
)
[11]:
plotting.plot_env(env=rt_custom)
[11]:
<matplotlib.axes._subplots.AxesSubplot at 0x1f325f99ac8>
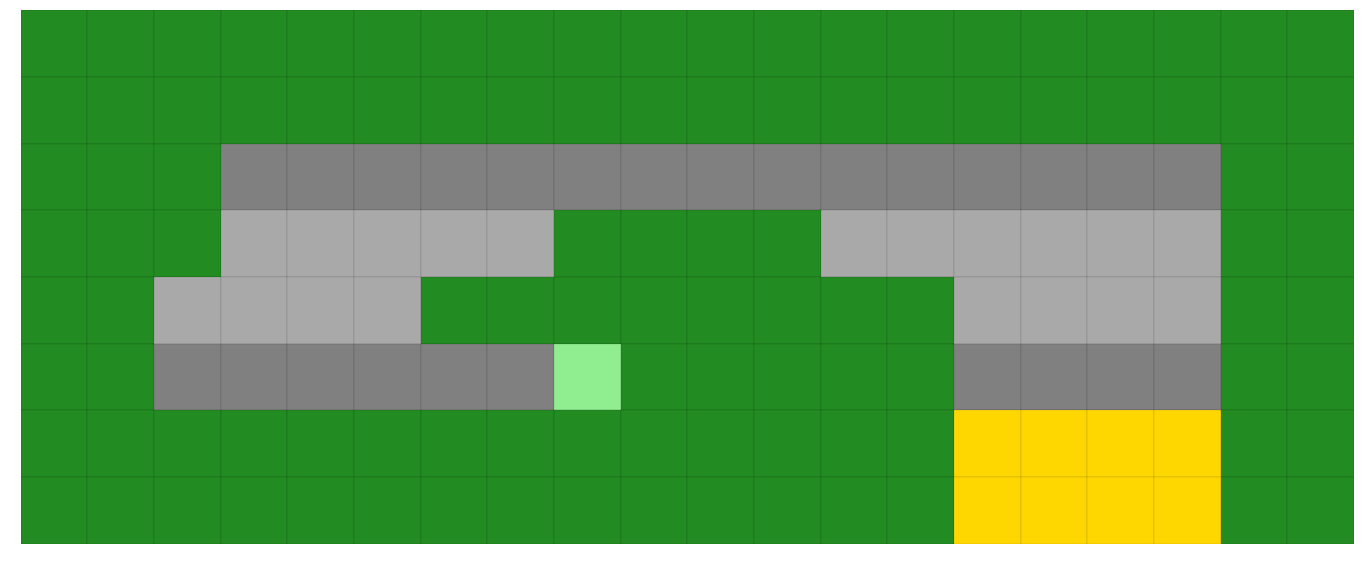
Solve with Value Iteration and Interrogate Solution¶
[12]:
rt_vi = solvers.ValueIteration(env=rt)
rt_vi.iterate_to_convergence()
16:33:21 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Solver iterating to convergence (Max delta in value function < 0.001 or iters>500)
16:33:23 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Solver converged to solution in 18 iterations
And we can then score our solution by running it multiple times through the environment
[13]:
scoring_data = rt_vi.score_policy(iters=500)
score_policy returns a EpisodeStatistics object that contains details from each episode taken during the scoring. Easiest way to interact with it is grabbing data as a dataframe
[14]:
print(f'type(scoring_data) = {type(scoring_data)}')
scoring_data_df = scoring_data.to_dataframe(include_episodes=True)
scoring_data_df.head(3)
type(scoring_data) = <class 'lrl.data_stores.data_stores.EpisodeStatistics'>
[14]:
| episode_index | reward | steps | terminal | reward_mean | reward_median | reward_std | reward_min | reward_max | steps_mean | steps_median | steps_std | steps_min | steps_max | terminal_fraction | episodes | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 91.0 | 11 | True | 91.0 | 91.0 | 0.0 | 91.0 | 91.0 | 11.0 | 11.0 | 0.0 | 11 | 11 | 1.0 | [(8, 2, 0, 0), (6, 2, -2, 0), (5, 3, -1, 1), (... |
| 1 | 1 | 91.0 | 11 | True | 91.0 | 91.0 | 0.0 | 91.0 | 91.0 | 11.0 | 11.0 | 0.0 | 11 | 11 | 1.0 | [(8, 2, 0, 0), (6, 2, -2, 0), (5, 3, -1, 1), (... |
| 2 | 2 | 91.0 | 11 | True | 91.0 | 91.0 | 0.0 | 91.0 | 91.0 | 11.0 | 11.0 | 0.0 | 11 | 11 | 1.0 | [(8, 2, 0, 0), (6, 2, -2, 0), (5, 3, -1, 1), (... |
[15]:
scoring_data_df.tail(3)
[15]:
| episode_index | reward | steps | terminal | reward_mean | reward_median | reward_std | reward_min | reward_max | steps_mean | steps_median | steps_std | steps_min | steps_max | terminal_fraction | episodes | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 497 | 497 | 91.0 | 11 | True | 90.473896 | 91.0 | 0.880581 | 89.0 | 91.0 | 11.526104 | 11.0 | 0.880581 | 11 | 13 | 1.0 | [(8, 2, 0, 0), (6, 2, -2, 0), (5, 3, -1, 1), (... |
| 498 | 498 | 91.0 | 11 | True | 90.474950 | 91.0 | 0.880013 | 89.0 | 91.0 | 11.525050 | 11.0 | 0.880013 | 11 | 13 | 1.0 | [(8, 2, 0, 0), (6, 2, -2, 0), (5, 3, -1, 1), (... |
| 499 | 499 | 91.0 | 11 | True | 90.476000 | 91.0 | 0.879445 | 89.0 | 91.0 | 11.524000 | 11.0 | 0.879445 | 11 | 13 | 1.0 | [(8, 2, 0, 0), (6, 2, -2, 0), (5, 3, -1, 1), (... |
Reward, Steps, and Terminal columns give data on that specific walk, whereas reward_mean, _median, etc. columns give aggregate scores up until that walk. For example:
[16]:
print(f'The reward obtained in the 499th episode was {scoring_data_df.loc[499, "reward"]}')
print(f'The mean reward obtained in the 0-499th episodes (inclusive) was {scoring_data_df.loc[499, "reward_mean"]}')
The reward obtained in the 499th episode was 91.0
The mean reward obtained in the 0-499th episodes (inclusive) was 90.476
And we can access the actual episode path for each episode
[17]:
print(f'Episode 0 (directly) : {scoring_data.episodes[0]}')
print(f'Episode 0 (from the dataframe): {scoring_data_df.loc[0, "episodes"]}')
Episode 0 (directly) : [(8, 2, 0, 0), (6, 2, -2, 0), (5, 3, -1, 1), (5, 5, 0, 2), (7, 7, 2, 2), (9, 7, 2, 0), (11, 7, 2, 0), (13, 6, 2, -1), (15, 4, 2, -2), (15, 2, 0, -2), (14, 0, -1, -2)]
Episode 0 (from the dataframe): [(8, 2, 0, 0), (6, 2, -2, 0), (5, 3, -1, 1), (5, 5, 0, 2), (7, 7, 2, 2), (9, 7, 2, 0), (11, 7, 2, 0), (13, 6, 2, -1), (15, 4, 2, -2), (15, 2, 0, -2), (14, 0, -1, -2)]
Plotting Results¶
And plot 100 randomly chosen episodes on the map, returned as a matplotlib axes
[18]:
ax_episodes = plotting.plot_episodes(episodes=scoring_data.episodes, env=rt, max_episodes=100, )
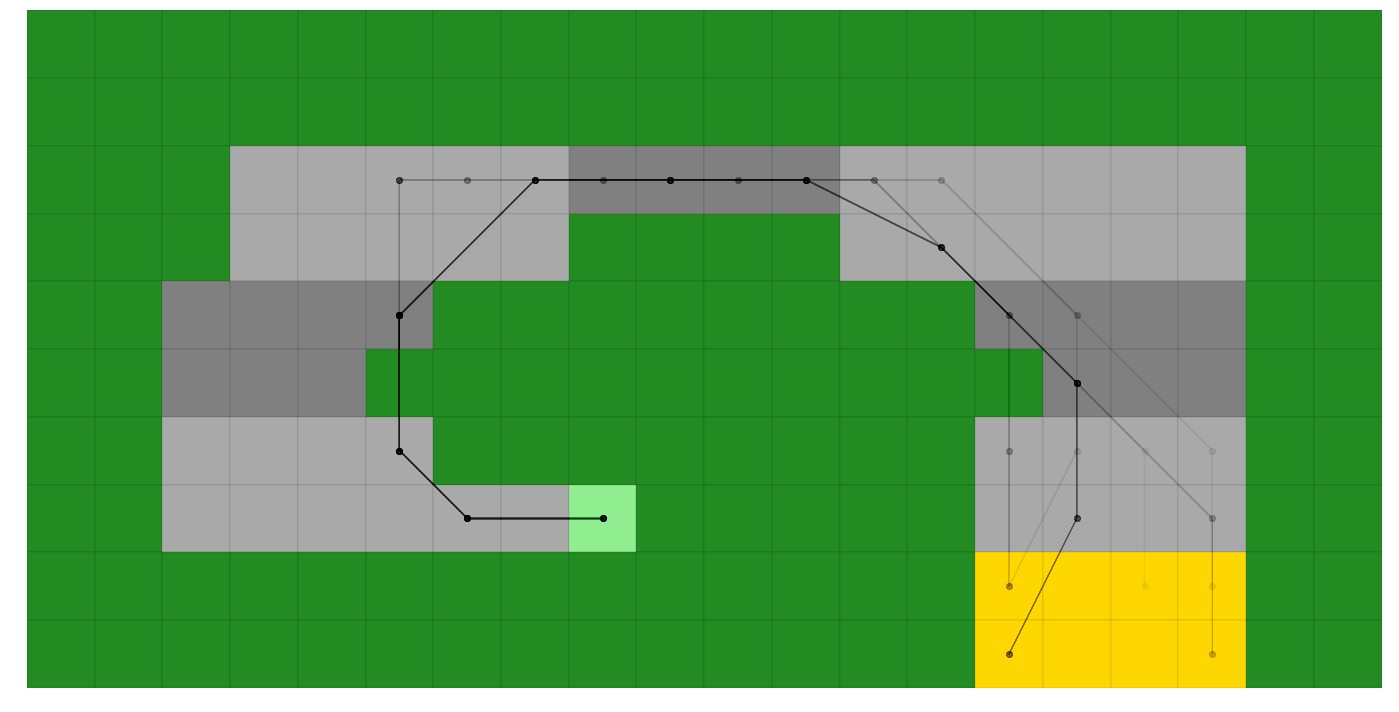
score_policy also lets us use hypothetical scenario, such as what if we started in a different starting location. Let’s try that by starting in the top left ((x,y) location (3, 7) (x=0 at left, y=0 at bot)) with a velocity of (1, -1), and plot it to our existing axes in red.
[19]:
scoring_data_alternate = rt_vi.score_policy(iters=500, initial_state=(3, 7, -2, -2))
ax_episodes_with_alternate = plotting.plot_episodes(episodes=scoring_data_alternate.episodes, env=rt,
add_env_to_plot=False, color='r', ax=ax_episodes
# savefig='my_figure_file', # If you wanted the figure to save directly
# to file, use savefig (used throughout
# lrl's plotting scripts)
)
# Must get_figure because we're reusing the figure from above and jupyter wont automatically reshow it
ax_episodes_with_alternate.get_figure()
[19]:
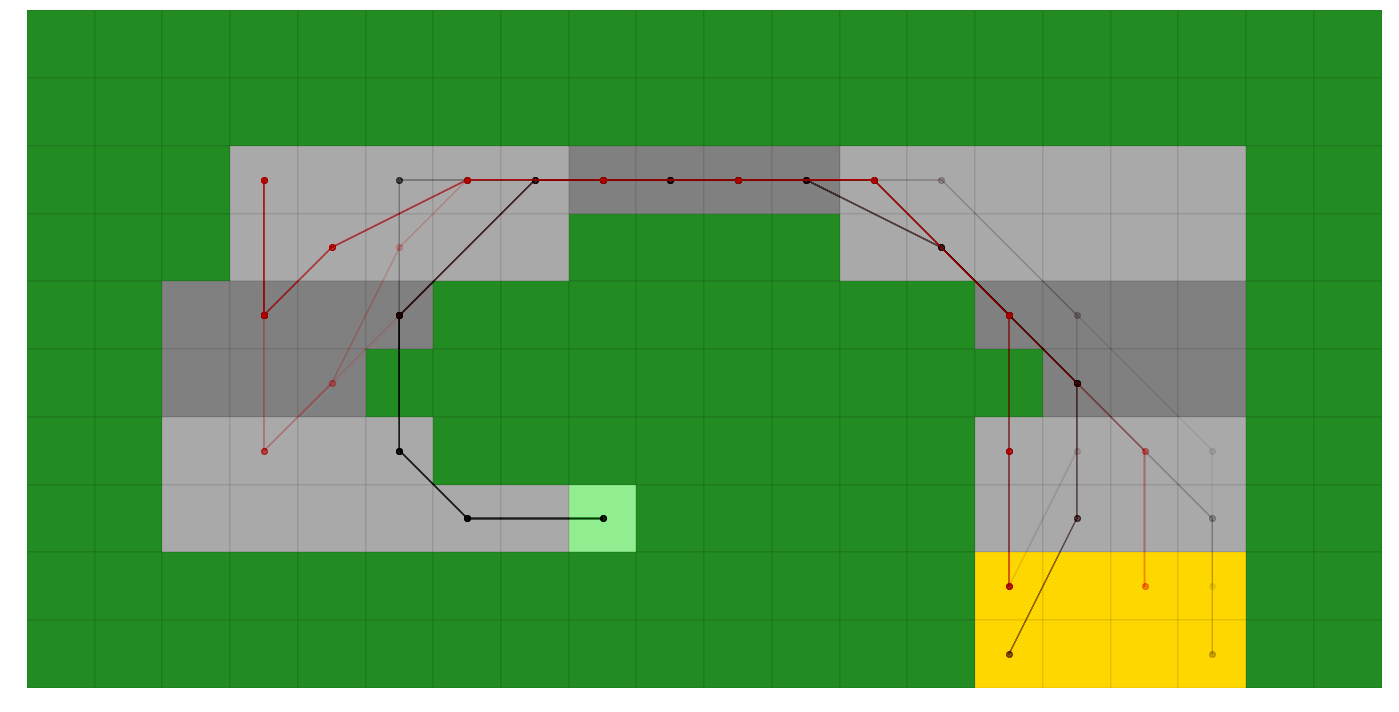
Where we can see the optimal policy takes a first action of (+2, 0) resulting in a first velocity of (0, -2) to avoid hitting the grass on step 1, then it redirects back up and around the track (although it sometimes slips on (3, 5) and drives down to (3, 3) before recovering)
We can also look at the Value function and best policy for all states
NOTE: Because state is (x, y, v_x, v_y), it is hard to capture all results on our (x, y) maps. plot_solver_results in this case plots a map for each (v_x, v_y) combination, with the axis title denoting which is the case.
[20]:
# Sorry, this will plot 24 plots normally.
# To keep concise, we turn matplotlib inline plotting off then back on and selectively plot a few examples
%matplotlib agg
ax_results = plotting.plot_solver_results(env=rt, solver=rt_vi)
%matplotlib inline
C:\Users\Scribs\Anaconda3\envs\lrl\lib\site-packages\matplotlib\pyplot.py:514: RuntimeWarning: More than 20 figures have been opened. Figures created through the pyplot interface (`matplotlib.pyplot.figure`) are retained until explicitly closed and may consume too much memory. (To control this warning, see the rcParam `figure.max_open_warning`).
max_open_warning, RuntimeWarning)
Plots are indexed by the additional state variables (v_x, v_y), so we can see the policy for v_x=0, v_y=0 like:
[21]:
ax_results[(0, 0)].get_figure()
[21]:
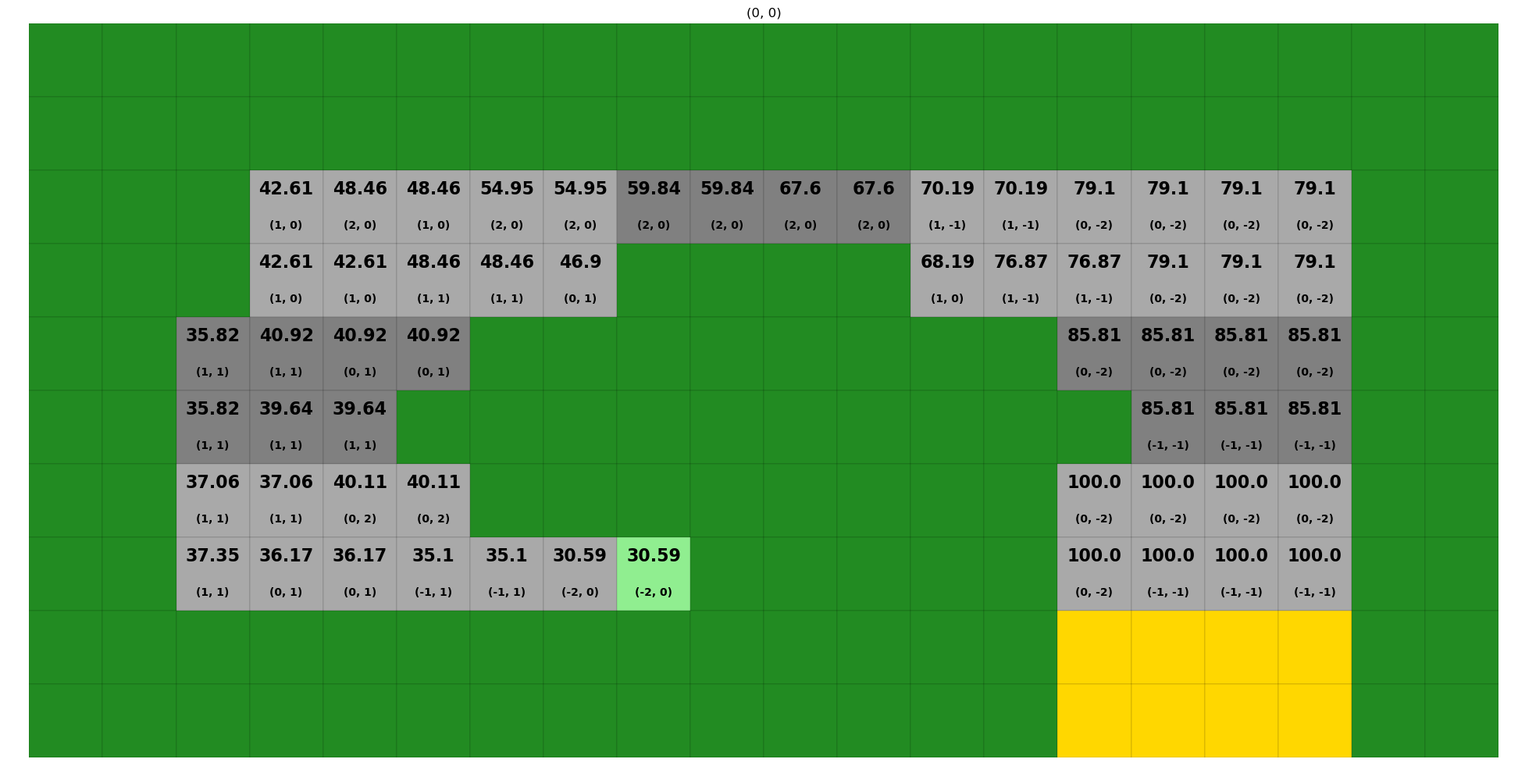
Where we can see the estimated value of the starting (light green) location is 30.59 (including discounting and costs for steps).
We can also look at the policy for (-2, -2) (the velocity for our alternate start used above in red):
[22]:
ax_results[(-2, -2)].get_figure()
[22]:
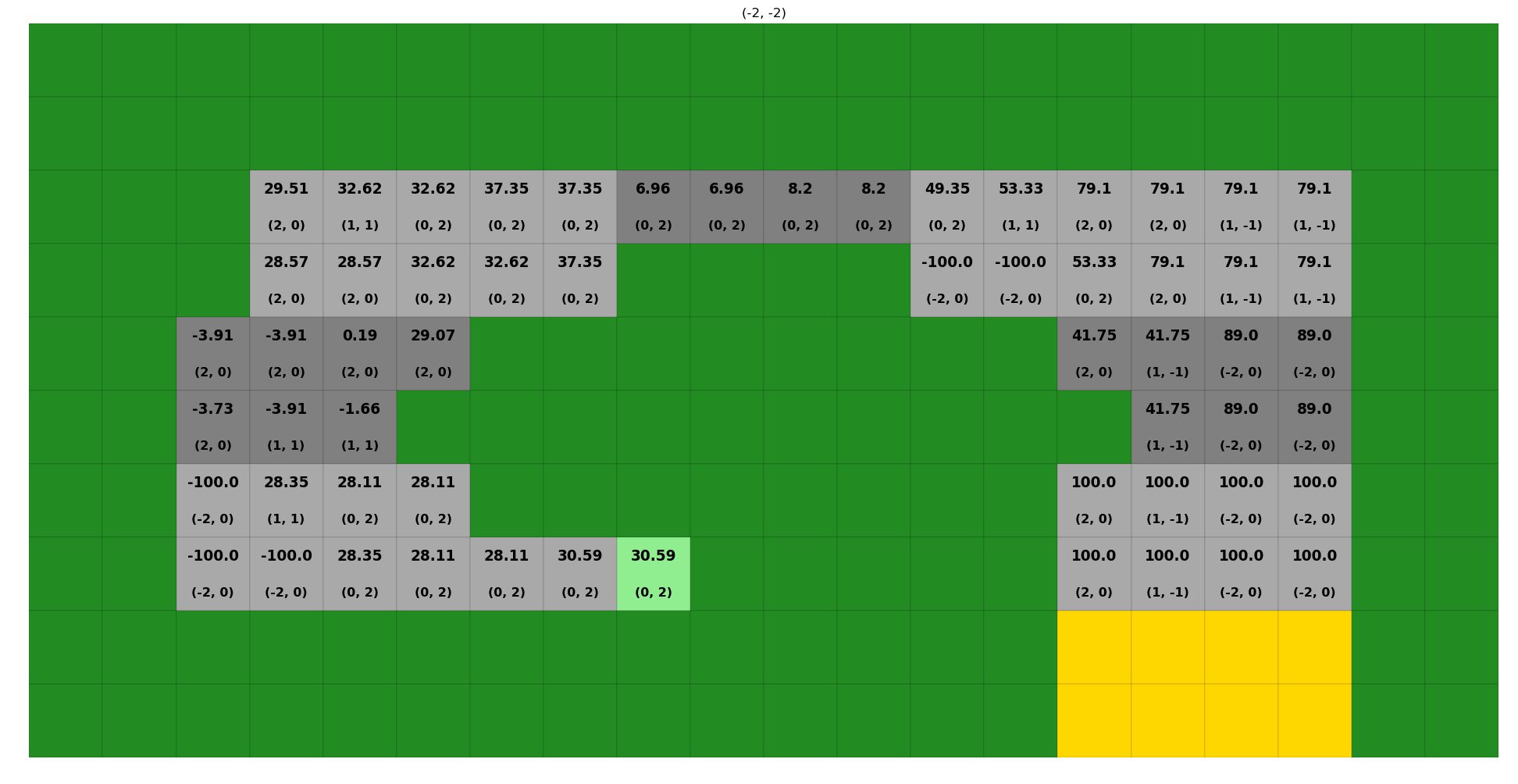
Where we in the top left tile (3, 7) the optimal policy is (2, 0), just as we saw in our red path plot above.
We can also see that tile (2, 2) (bottom left) has a -100 value because it is impossible to not crash with a (-2, -2) initialial velocity from tile (2, 2) given that our acceleration limit is 2.
Solving with Policy Iteration and Comparing to Value Iteration¶
We can also use other solvers
[23]:
rt_pi = solvers.PolicyIteration(env=rt)
rt_pi.iterate_to_convergence()
16:33:37 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Solver iterating to convergence (1 iteration without change in policy or iters>500)
16:33:39 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Solver converged to solution in 6 iterations
We can look at how PI and VI converged relative to each other, comparing the maximum change in value function for each iteration
[24]:
# (these are simple convenience functions for plotting, basically just recipes. See the plotting API)
# We can pass the solver..
ax = plotting.plot_solver_convergence(rt_vi, label='vi')
# Or going a little deeper into the API, with style being passed to matplotlib's plot function...
ax = plotting.plot_solver_convergence_from_df(rt_pi.iteration_data.to_dataframe(), y='delta_max', x='iteration', ax=ax, label='pi', ls='', marker='o')
ax.legend()
[24]:
<matplotlib.legend.Legend at 0x1f33ad329e8>
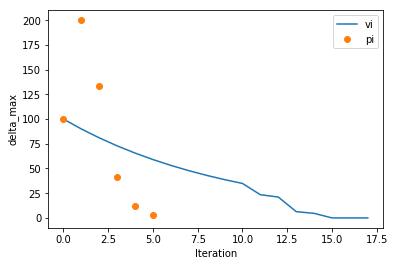
And looking at policy changes per iteration
[25]:
# (these are simple convenience functions for plotting, basically just recipes. See the plotting API)
# We can pass the solver..
ax = plotting.plot_solver_convergence(rt_vi, y='policy_changes', label='vi')
# Or going a little deeper into the API...
ax = plotting.plot_solver_convergence_from_df(rt_pi.iteration_data.to_dataframe(), y='policy_changes', x='iteration', ax=ax, label='pi', ls='', marker='o')
ax.legend()
[25]:
<matplotlib.legend.Legend at 0x1f33be75780>
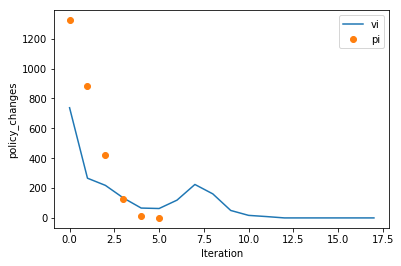
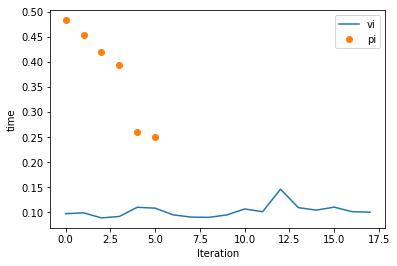
So we can see PI accomplishes more per iteration. But, is it faster? Let’s look at time per iteration
[26]:
# (these are simple convenience functions for plotting, basically just recipes. See the plotting API)
# We can pass the solver..
ax = plotting.plot_solver_convergence(rt_vi, y='time', label='vi')
# Or going a little deeper into the API...
ax = plotting.plot_solver_convergence_from_df(rt_pi.iteration_data.to_dataframe(), y='time', x='iteration', ax=ax, label='pi', ls='', marker='o')
ax.legend()
print(f'Total solution time for Value Iteration (excludes any scoring time): {rt_vi.iteration_data.to_dataframe().loc[:, "time"].sum():.2f}s')
print(f'Total solution time for Policy Iteration (excludes any scoring time): {rt_pi.iteration_data.to_dataframe().loc[:, "time"].sum():.2f}s')
Total solution time for Value Iteration (excludes any scoring time): 1.85s
Total solution time for Policy Iteration (excludes any scoring time): 2.26s
Solve with Q-Learning¶
We can also use QLearning, although it needs a few parameters
[27]:
# Let's be explicit with our QLearning settings for alpha and epsilon
alpha = 0.1 # Constant alpha during learning
# Decay function for epsilon (see QLearning() and decay_functions() in documentation for syntax)
# Decay epsilon linearly from 0.2 at timestep (iteration) 0 to 0.05 at timestep 1500,
# keeping constant at 0.05 for ts>1500
epsilon = {
'type': 'linear',
'initial_value': 0.2,
'initial_timestep': 0,
'final_value': 0.05,
'final_timestep': 1500
}
# Above PI/VI used the default gamma, but we will specify one here
gamma = 0.9
# Convergence is kinda tough to interpret automatically for Q-Learning. One good way to monitor convergence is to
# evaluate how good the greedy policy at a given point in the solution is and decide if it is still improving.
# We can enable this with score_while_training (available for Value and Policy Iteration as well)
# NOTE: During scoring runs, the solver is acting greedily and NOT learning from the environment. These are separate
# runs solely used to estimate solution progress
# NOTE: Scoring every 50 iterations is probably a bit much, but used to show a nice plot below. The default 500/500
# is probably a better general guidance
score_while_training = {
'n_trains_per_eval': 50, # Number of training episodes we run per attempt to score the greedy policy
# (eg: Here we do a scoring run after every 500 training episodes, where training episodes
# are the usual epsilon-greedy exploration episodes)
'n_evals': 250, # Number of times we run through the env with the greedy policy whenever we score
}
# score_while_training = True # This calls the default settings, which are also 500/500 like above
rt_ql = solvers.QLearning(env=rt, alpha=alpha, epsilon=epsilon, gamma=gamma,
max_iters=5000, score_while_training=score_while_training)
(note how long Q-Learning takes for this environment versus the planning algorithms)
[28]:
rt_ql.iterate_to_convergence()
16:33:41 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Solver iterating to convergence (20 episodes with max delta in Q function < 0.1 or iters>5000)
16:33:41 - lrl.solvers.learners - iterate - INFO - Performing iteration (episode) 0 of Q-Learning
16:33:41 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 50
16:33:42 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -103.0, r_max = -103.0
16:33:42 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 100
16:33:43 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -103.0, r_max = -103.0
16:33:43 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 150
16:33:43 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -103.0, r_max = -103.0
16:33:44 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 200
16:33:44 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -102.0, r_max = -102.0
16:33:44 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 250
16:33:45 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -103.424, r_max = -102.0
16:33:45 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 300
16:33:46 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -100.0, r_max = -100.0
16:33:46 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 350
16:33:46 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -103.0, r_max = -103.0
16:33:46 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 400
16:33:47 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -104.224, r_max = -104.0
16:33:47 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 450
16:33:47 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -103.0, r_max = -103.0
16:33:48 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 500
16:33:48 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -104.22, r_max = -104.0
16:33:48 - lrl.solvers.learners - iterate - INFO - Performing iteration (episode) 500 of Q-Learning
16:33:48 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 550
16:33:49 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -104.264, r_max = -104.0
16:33:49 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 600
16:33:50 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -104.0, r_max = -104.0
16:33:50 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 650
16:33:50 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -104.0, r_max = -104.0
16:33:50 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 700
16:33:51 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -104.228, r_max = -104.0
16:33:51 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 750
16:33:52 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -106.0, r_max = -106.0
16:33:52 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 800
16:33:52 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -104.464, r_max = -104.0
16:33:53 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 850
16:33:53 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -105.0, r_max = -105.0
16:33:53 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 900
16:33:54 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -105.0, r_max = -105.0
16:33:54 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 950
16:33:54 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -106.824, r_max = -105.0
16:33:55 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 1000
16:33:55 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -104.54, r_max = -104.0
16:33:55 - lrl.solvers.learners - iterate - INFO - Performing iteration (episode) 1000 of Q-Learning
16:33:55 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 1050
16:33:56 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -104.0, r_max = -104.0
16:33:56 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 1100
16:33:57 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -100.0, r_max = -100.0
16:33:57 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 1150
16:33:57 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -103.796, r_max = -103.0
16:33:58 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 1200
16:33:58 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -106.128, r_max = -106.0
16:33:58 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 1250
16:33:59 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -104.0, r_max = -104.0
16:33:59 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 1300
16:34:00 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -107.852, r_max = -107.0
16:34:00 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 1350
16:34:00 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -105.416, r_max = -104.0
16:34:01 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 1400
16:34:01 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -100.0, r_max = -100.0
16:34:02 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 1450
16:34:02 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -108.08, r_max = -108.0
16:34:02 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 1500
16:34:03 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -105.84, r_max = -105.0
16:34:03 - lrl.solvers.learners - iterate - INFO - Performing iteration (episode) 1500 of Q-Learning
16:34:03 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 1550
16:34:03 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -108.224, r_max = -108.0
16:34:04 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 1600
16:34:04 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -104.0, r_max = -104.0
16:34:04 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 1650
16:34:05 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -106.0, r_max = -106.0
16:34:05 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 1700
16:34:06 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -100.0, r_max = -100.0
16:34:06 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 1750
16:34:07 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -104.78, r_max = -104.0
16:34:07 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 1800
16:34:07 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -112.76, r_max = -111.0
16:34:08 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 1850
16:34:08 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -104.732, r_max = -104.0
16:34:08 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 1900
16:34:09 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -117.248, r_max = -117.0
16:34:09 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 1950
16:34:10 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -100.0, r_max = -100.0
16:34:10 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 2000
16:34:10 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -106.0, r_max = -106.0
16:34:10 - lrl.solvers.learners - iterate - INFO - Performing iteration (episode) 2000 of Q-Learning
16:34:11 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 2050
16:34:11 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -107.12, r_max = -100.0
16:34:12 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 2100
16:34:12 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -115.0, r_max = -115.0
16:34:12 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 2150
16:34:13 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -102.516, r_max = -100.0
16:34:13 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 2200
16:34:14 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -105.72, r_max = -105.0
16:34:14 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 2250
16:34:14 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -109.88, r_max = -109.0
16:34:15 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 2300
16:34:15 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -105.496, r_max = -105.0
16:34:16 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 2350
16:34:16 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -108.12, r_max = -104.0
16:34:16 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 2400
16:34:17 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -107.168, r_max = -100.0
16:34:17 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 2450
16:34:17 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -107.34, r_max = -106.0
16:34:18 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 2500
16:34:18 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -105.568, r_max = -105.0
16:34:18 - lrl.solvers.learners - iterate - INFO - Performing iteration (episode) 2500 of Q-Learning
16:34:18 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 2550
16:34:19 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -106.0, r_max = -106.0
16:34:19 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 2600
16:34:20 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -108.0, r_max = -108.0
16:34:20 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 2650
16:34:21 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -111.952, r_max = -108.0
16:34:21 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 2700
16:34:21 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -107.512, r_max = -106.0
16:34:22 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 2750
16:34:22 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -120.848, r_max = -115.0
16:34:22 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 2800
16:34:23 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -110.376, r_max = -110.0
16:34:23 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 2850
16:34:24 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -112.776, r_max = -111.0
16:34:24 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 2900
16:34:24 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -103.8, r_max = -100.0
16:34:25 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 2950
16:34:25 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -107.868, r_max = -106.0
16:34:26 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 3000
16:34:26 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -101.668, r_max = -100.0
16:34:26 - lrl.solvers.learners - iterate - INFO - Performing iteration (episode) 3000 of Q-Learning
16:34:27 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 3050
16:34:27 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -49.848, r_max = 89.0
16:34:27 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 3100
16:34:28 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -101.392, r_max = -100.0
16:34:28 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 3150
16:34:29 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -114.236, r_max = 77.0
16:34:29 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 3200
16:34:30 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -106.996, r_max = -106.0
16:34:30 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 3250
16:34:30 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -124.144, r_max = -100.0
16:34:31 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 3300
16:34:31 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -109.284, r_max = -106.0
16:34:32 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 3350
16:34:32 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -102.112, r_max = -100.0
16:34:33 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 3400
16:34:33 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -114.396, r_max = -105.0
16:34:34 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 3450
16:34:34 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -100.0, r_max = -100.0
16:34:35 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 3500
16:34:35 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -100.0, r_max = -100.0
16:34:35 - lrl.solvers.learners - iterate - INFO - Performing iteration (episode) 3500 of Q-Learning
16:34:36 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 3550
16:34:36 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 36.04, r_max = 89.0
16:34:37 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 3600
16:34:37 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -109.624, r_max = -107.0
16:34:37 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 3650
16:34:38 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = -87.048, r_max = 87.0
16:34:38 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 3700
16:34:39 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 90.472, r_max = 91.0
16:34:39 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 3750
16:34:40 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 90.536, r_max = 91.0
16:34:40 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 3800
16:34:40 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 90.488, r_max = 91.0
16:34:41 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 3850
16:34:41 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 90.416, r_max = 91.0
16:34:41 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 3900
16:34:42 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 90.464, r_max = 91.0
16:34:42 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 3950
16:34:42 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 90.392, r_max = 91.0
16:34:43 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 4000
16:34:43 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 90.432, r_max = 91.0
16:34:43 - lrl.solvers.learners - iterate - INFO - Performing iteration (episode) 4000 of Q-Learning
16:34:44 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 4050
16:34:44 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 90.52, r_max = 91.0
16:34:44 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 4100
16:34:45 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 90.424, r_max = 91.0
16:34:45 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 4150
16:34:45 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 90.4, r_max = 91.0
16:34:46 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 4200
16:34:46 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 90.504, r_max = 91.0
16:34:46 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 4250
16:34:47 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 90.544, r_max = 91.0
16:34:47 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 4300
16:34:48 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 90.544, r_max = 91.0
16:34:48 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 4350
16:34:48 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 90.424, r_max = 91.0
16:34:49 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 4400
16:34:49 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 90.512, r_max = 91.0
16:34:49 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 4450
16:34:50 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 90.552, r_max = 91.0
16:34:50 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 4500
16:34:51 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 90.536, r_max = 91.0
16:34:51 - lrl.solvers.learners - iterate - INFO - Performing iteration (episode) 4500 of Q-Learning
16:34:51 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 4550
16:34:51 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 90.544, r_max = 91.0
16:34:52 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 4600
16:34:52 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 90.48, r_max = 91.0
16:34:52 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 4650
16:34:53 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 90.504, r_max = 91.0
16:34:53 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 4700
16:34:54 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 90.544, r_max = 91.0
16:34:54 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 4750
16:34:54 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 90.472, r_max = 91.0
16:34:55 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 4800
16:34:55 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 90.728, r_max = 91.0
16:34:55 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 4850
16:34:56 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 90.52, r_max = 91.0
16:34:56 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 4900
16:34:56 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 90.584, r_max = 91.0
16:34:57 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 4950
16:34:57 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 90.496, r_max = 91.0
16:34:57 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy being scored 250 times at iteration 5000
16:34:58 - lrl.solvers.base_solver - iterate_to_convergence - INFO - Current greedy policy achieved: r_mean = 90.408, r_max = 91.0
16:34:58 - lrl.solvers.base_solver - iterate_to_convergence - WARNING - Max iterations (5000) reached - solver did not converge
Like above, we can plot the number of policy changes per iteration. But this plot looks very different from above and shows one view of why Q-Learning takes many more iterations (each iteration accomplishes a lot less learning than a planning algorithm)
[29]:
rt_ql_iter_df = rt_ql.iteration_data.to_dataframe()
rt_ql_iter_df.plot(x='iteration', y='policy_changes', kind='scatter', )
[29]:
<matplotlib.axes._subplots.AxesSubplot at 0x1f33bf52cc0>
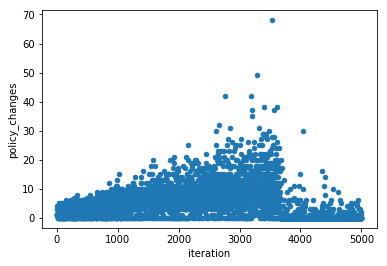
We can access the intermediate scoring through the scoring_summary (GeneralIterationData) and scoring_episode_statistics (EpisodeStatistics) objects
[30]:
rt_ql_intermediate_scoring_df = rt_ql.scoring_summary.to_dataframe()
rt_ql_intermediate_scoring_df
[30]:
| iteration | reward_mean | reward_median | reward_std | reward_min | reward_max | steps_mean | steps_median | steps_std | steps_min | steps_max | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 50 | -103.000 | -103.0 | 0.000000 | -103.0 | -103.0 | 5.000 | 5.0 | 0.000000 | 5 | 5 |
| 1 | 100 | -103.000 | -103.0 | 0.000000 | -103.0 | -103.0 | 5.000 | 5.0 | 0.000000 | 5 | 5 |
| 2 | 150 | -103.000 | -103.0 | 0.000000 | -103.0 | -103.0 | 5.000 | 5.0 | 0.000000 | 5 | 5 |
| 3 | 200 | -102.000 | -102.0 | 0.000000 | -102.0 | -102.0 | 4.000 | 4.0 | 0.000000 | 4 | 4 |
| 4 | 250 | -103.424 | -104.0 | 0.905662 | -104.0 | -102.0 | 5.424 | 6.0 | 0.905662 | 4 | 6 |
| 5 | 300 | -100.000 | -100.0 | 0.000000 | -100.0 | -100.0 | 101.000 | 101.0 | 0.000000 | 101 | 101 |
| 6 | 350 | -103.000 | -103.0 | 0.000000 | -103.0 | -103.0 | 5.000 | 5.0 | 0.000000 | 5 | 5 |
| 7 | 400 | -104.224 | -104.0 | 0.416922 | -105.0 | -104.0 | 6.224 | 6.0 | 0.416922 | 6 | 7 |
| 8 | 450 | -103.000 | -103.0 | 0.000000 | -103.0 | -103.0 | 5.000 | 5.0 | 0.000000 | 5 | 5 |
| 9 | 500 | -104.220 | -104.0 | 0.414246 | -105.0 | -104.0 | 6.220 | 6.0 | 0.414246 | 6 | 7 |
| 10 | 550 | -104.264 | -104.0 | 0.440799 | -105.0 | -104.0 | 6.264 | 6.0 | 0.440799 | 6 | 7 |
| 11 | 600 | -104.000 | -104.0 | 0.000000 | -104.0 | -104.0 | 6.000 | 6.0 | 0.000000 | 6 | 6 |
| 12 | 650 | -104.000 | -104.0 | 0.000000 | -104.0 | -104.0 | 6.000 | 6.0 | 0.000000 | 6 | 6 |
| 13 | 700 | -104.228 | -104.0 | 0.419543 | -105.0 | -104.0 | 6.228 | 6.0 | 0.419543 | 6 | 7 |
| 14 | 750 | -106.000 | -106.0 | 0.000000 | -106.0 | -106.0 | 8.000 | 8.0 | 0.000000 | 8 | 8 |
| 15 | 800 | -104.464 | -104.0 | 0.844218 | -106.0 | -104.0 | 6.464 | 6.0 | 0.844218 | 6 | 8 |
| 16 | 850 | -105.000 | -105.0 | 0.000000 | -105.0 | -105.0 | 7.000 | 7.0 | 0.000000 | 7 | 7 |
| 17 | 900 | -105.000 | -105.0 | 0.000000 | -105.0 | -105.0 | 7.000 | 7.0 | 0.000000 | 7 | 7 |
| 18 | 950 | -106.824 | -107.0 | 1.302699 | -109.0 | -105.0 | 8.824 | 9.0 | 1.302699 | 7 | 11 |
| 19 | 1000 | -104.540 | -104.0 | 1.152562 | -107.0 | -104.0 | 6.540 | 6.0 | 1.152562 | 6 | 9 |
| 20 | 1050 | -104.000 | -104.0 | 0.000000 | -104.0 | -104.0 | 6.000 | 6.0 | 0.000000 | 6 | 6 |
| 21 | 1100 | -100.000 | -100.0 | 0.000000 | -100.0 | -100.0 | 101.000 | 101.0 | 0.000000 | 101 | 101 |
| 22 | 1150 | -103.796 | -104.0 | 0.402969 | -104.0 | -103.0 | 5.796 | 6.0 | 0.402969 | 5 | 6 |
| 23 | 1200 | -106.128 | -106.0 | 0.489506 | -108.0 | -106.0 | 8.128 | 8.0 | 0.489506 | 8 | 10 |
| 24 | 1250 | -104.000 | -104.0 | 0.000000 | -104.0 | -104.0 | 6.000 | 6.0 | 0.000000 | 6 | 6 |
| 25 | 1300 | -107.852 | -107.0 | 1.352810 | -110.0 | -107.0 | 9.852 | 9.0 | 1.352810 | 9 | 12 |
| 26 | 1350 | -105.416 | -106.0 | 0.909365 | -106.0 | -104.0 | 7.416 | 8.0 | 0.909365 | 6 | 8 |
| 27 | 1400 | -100.000 | -100.0 | 0.000000 | -100.0 | -100.0 | 101.000 | 101.0 | 0.000000 | 101 | 101 |
| 28 | 1450 | -108.080 | -108.0 | 0.271293 | -109.0 | -108.0 | 10.080 | 10.0 | 0.271293 | 10 | 11 |
| 29 | 1500 | -105.840 | -105.0 | 1.474585 | -112.0 | -105.0 | 7.840 | 7.0 | 1.474585 | 7 | 14 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 70 | 3550 | 36.040 | 89.0 | 87.544037 | -116.0 | 89.0 | 12.360 | 13.0 | 2.076150 | 9 | 18 |
| 71 | 3600 | -109.624 | -107.0 | 4.556602 | -131.0 | -107.0 | 11.624 | 9.0 | 4.556602 | 9 | 33 |
| 72 | 3650 | -87.048 | -100.0 | 53.641902 | -113.0 | 87.0 | 64.860 | 101.0 | 43.202042 | 11 | 101 |
| 73 | 3700 | 90.472 | 91.0 | 0.881599 | 89.0 | 91.0 | 11.528 | 11.0 | 0.881599 | 11 | 13 |
| 74 | 3750 | 90.536 | 91.0 | 0.844218 | 89.0 | 91.0 | 11.464 | 11.0 | 0.844218 | 11 | 13 |
| 75 | 3800 | 90.488 | 91.0 | 0.872844 | 89.0 | 91.0 | 11.512 | 11.0 | 0.872844 | 11 | 13 |
| 76 | 3850 | 90.416 | 91.0 | 0.909365 | 89.0 | 91.0 | 11.584 | 11.0 | 0.909365 | 11 | 13 |
| 77 | 3900 | 90.464 | 91.0 | 0.885835 | 89.0 | 91.0 | 11.536 | 11.0 | 0.885835 | 11 | 13 |
| 78 | 3950 | 90.392 | 91.0 | 0.919965 | 89.0 | 91.0 | 11.608 | 11.0 | 0.919965 | 11 | 13 |
| 79 | 4000 | 90.432 | 91.0 | 0.901874 | 89.0 | 91.0 | 11.568 | 11.0 | 0.901874 | 11 | 13 |
| 80 | 4050 | 90.520 | 91.0 | 0.854166 | 89.0 | 91.0 | 11.480 | 11.0 | 0.854166 | 11 | 13 |
| 81 | 4100 | 90.424 | 91.0 | 0.905662 | 89.0 | 91.0 | 11.576 | 11.0 | 0.905662 | 11 | 13 |
| 82 | 4150 | 90.400 | 91.0 | 0.916515 | 89.0 | 91.0 | 11.600 | 11.0 | 0.916515 | 11 | 13 |
| 83 | 4200 | 90.504 | 91.0 | 0.863704 | 89.0 | 91.0 | 11.496 | 11.0 | 0.863704 | 11 | 13 |
| 84 | 4250 | 90.544 | 91.0 | 0.839085 | 89.0 | 91.0 | 11.456 | 11.0 | 0.839085 | 11 | 13 |
| 85 | 4300 | 90.544 | 91.0 | 0.839085 | 89.0 | 91.0 | 11.456 | 11.0 | 0.839085 | 11 | 13 |
| 86 | 4350 | 90.424 | 91.0 | 0.905662 | 89.0 | 91.0 | 11.576 | 11.0 | 0.905662 | 11 | 13 |
| 87 | 4400 | 90.512 | 91.0 | 0.858985 | 89.0 | 91.0 | 11.488 | 11.0 | 0.858985 | 11 | 13 |
| 88 | 4450 | 90.552 | 91.0 | 0.833844 | 89.0 | 91.0 | 11.448 | 11.0 | 0.833844 | 11 | 13 |
| 89 | 4500 | 90.536 | 91.0 | 0.844218 | 89.0 | 91.0 | 11.464 | 11.0 | 0.844218 | 11 | 13 |
| 90 | 4550 | 90.544 | 91.0 | 0.839085 | 89.0 | 91.0 | 11.456 | 11.0 | 0.839085 | 11 | 13 |
| 91 | 4600 | 90.480 | 91.0 | 0.877268 | 89.0 | 91.0 | 11.520 | 11.0 | 0.877268 | 11 | 13 |
| 92 | 4650 | 90.504 | 91.0 | 0.863704 | 89.0 | 91.0 | 11.496 | 11.0 | 0.863704 | 11 | 13 |
| 93 | 4700 | 90.544 | 91.0 | 0.839085 | 89.0 | 91.0 | 11.456 | 11.0 | 0.839085 | 11 | 13 |
| 94 | 4750 | 90.472 | 91.0 | 0.881599 | 89.0 | 91.0 | 11.528 | 11.0 | 0.881599 | 11 | 13 |
| 95 | 4800 | 90.728 | 91.0 | 0.685577 | 89.0 | 91.0 | 11.272 | 11.0 | 0.685577 | 11 | 13 |
| 96 | 4850 | 90.520 | 91.0 | 0.854166 | 89.0 | 91.0 | 11.480 | 11.0 | 0.854166 | 11 | 13 |
| 97 | 4900 | 90.584 | 91.0 | 0.811754 | 89.0 | 91.0 | 11.416 | 11.0 | 0.811754 | 11 | 13 |
| 98 | 4950 | 90.496 | 91.0 | 0.868323 | 89.0 | 91.0 | 11.504 | 11.0 | 0.868323 | 11 | 13 |
| 99 | 5000 | 90.408 | 91.0 | 0.912982 | 89.0 | 91.0 | 11.592 | 11.0 | 0.912982 | 11 | 13 |
100 rows × 11 columns
[31]:
plt.plot(rt_ql_intermediate_scoring_df.loc[:, 'iteration'], rt_ql_intermediate_scoring_df.loc[:, 'reward_mean'], '-o')
[31]:
[<matplotlib.lines.Line2D at 0x1f33df6ca90>]
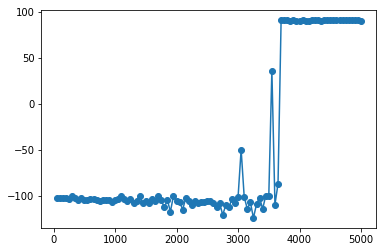
In this case we see somewhere between the 3500th and 4000th iteration the solver finds a solution and starts building a policy around it. This won’t always be the case and learning may be more incremental
And if we wanted to access the actual episodes that went into one of these datapoints, they’re available in a dictionary of EpisodeStatistics objects here (keyed by iteration number):
[33]:
i = 3750
print(f'EpisodeStatistics for the scoring at iter == {i}:\n')
rt_ql.scoring_episode_statistics[i].to_dataframe().head()
EpisodeStatistics for the scoring at iter == 3750:
[33]:
| episode_index | reward | steps | terminal | reward_mean | reward_median | reward_std | reward_min | reward_max | steps_mean | steps_median | steps_std | steps_min | steps_max | terminal_fraction | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 91.0 | 11 | True | 91.0 | 91.0 | 0.000000 | 91.0 | 91.0 | 11.0 | 11.0 | 0.000000 | 11 | 11 | 1.0 |
| 1 | 1 | 91.0 | 11 | True | 91.0 | 91.0 | 0.000000 | 91.0 | 91.0 | 11.0 | 11.0 | 0.000000 | 11 | 11 | 1.0 |
| 2 | 2 | 91.0 | 11 | True | 91.0 | 91.0 | 0.000000 | 91.0 | 91.0 | 11.0 | 11.0 | 0.000000 | 11 | 11 | 1.0 |
| 3 | 3 | 89.0 | 13 | True | 90.5 | 91.0 | 0.866025 | 89.0 | 91.0 | 11.5 | 11.0 | 0.866025 | 11 | 13 | 1.0 |
| 4 | 4 | 89.0 | 13 | True | 90.2 | 91.0 | 0.979796 | 89.0 | 91.0 | 11.8 | 11.0 | 0.979796 | 11 | 13 | 1.0 |